Posts about Fun with SQL
Crazy Idea to Postgres in the Browser
We've got Postgres running in a web browser and lots of folks were curious how it was built. Joey goes through the prototyping steps.
5 min readRise of the Anti-Join
Find me all the things in set "A" that are not in set "B". Paul has some suggestions of when to use the anti-join pattern in queries with some impressive results.
5 min readQuick and Easy Postgres Data Compare
Brian offers a quick and efficient way to compare data between two different Postgres sources using the Postgres Foreign Data Wrapper (postgres_fdw).
9 min readParquet and Postgres in the Data Lake
Have too much static data? Paul has a idea of moving some of it to a datalake. He provides a walk-through of setting up Parquet with Postgres using the parquet_fdw.
8 min readHow to Cheat at WORDLE with PostgreSQL
Fun with PostgreSQL! Using the French Wordle list, this post shows you some sql to find out the most often used letters in a table, how to reduce possibilities once you’ve found some letters, and how to solve wordle puzzles using the back end.
13 min read
Extracting and Substituting Text with Regular Expressions in PostgreSQL
Regular expressions? Exceptional expressions according to Paul! Some nice examples and tips for using regrex inside Postgres. Topics include true/false regex, text extraction, text substitutions, and using regex flags.
5 min read
Fun with SQL in Postgres: Finding Revenue Accrued Per Day
Some helpful queries and examples for revenue accruing per day over the course of a month.
6 min read
Projecting Monthly Revenue Run Rate in Postgres
Calculate and project monthly recurring revenue (MRR) and annual recurring revenue (ARR) with PostgreSQL.
8 min read
Devious SQL: Dynamic DDL in PostgreSQL
Data Definition Language (DDL) in SQL itself is notoriously non-dynamic but this next post on Devious SQL provides some examples of Dynamic DDL Postgres syntax for utility queries where you need to review the current state of the database.
6 min read
Devious SQL: Message Queuing Using Native PostgreSQL
An interesting question came up on the postgresql IRC channel about how to use native PostgreSQL features to handle some sort of queuing behavior. While the specific usage was related to handling serialization of specific events to some external broker, the specifics are less important than the overall structure.
8 min read.jpg)
Fast, Flexible Summaries with Aggregate Filters and Windows
PostgreSQL can provide high performance summaries over multi-million record tables, and supports some great SQL sugar to make it concise and readable, in particular aggregate filtering, a feature unique to PostgreSQL and SQLite.
3 min read.png)
Fun with pg_checksums
Data checksums are a great feature in PostgreSQL. They are used to detect any corruption of the data that Postgres stores on disk. Every system we develop at Crunchy Data has this feature enabled by default. It's not only Postgres itself that can make use of these checksums.
10 min read.jpg)
Devious SQL: Run the Same Query Against Tables With Differing Columns
We spend time day in, day out, answering the questions that matter and coming up with solutions that make the most sense. However, sometimes a question comes up that is just so darn … interesting that even if there are sensible solutions or workarounds, it still seems like a challenge just to take the request literally. Thus was born this blog series, Devious SQL. (Devious - longer and less direct than the most straightforward way.)
6 min read
Simulating UPDATE or DELETE with LIMIT in Postgres: CTEs to The Rescue!
There have certainly been times when using PostgreSQL, that I’ve yearned for an UPDATE or DELETE statement with a LIMIT feature. While the SQL standard itself has no say in the matter as of SQL:2016, there are definite cases of existing SQL database dialects that support this.
10 min read
Musings of a PostgreSQL Data Pontiff Episode 1
This is the first in a series of blogs on the topic of using PostgreSQL for "data science". I put that in quotes because I would not consider myself to be a practicing "data scientist", per se. Of course I'm not sure there is a universally accepted definition of "data scientist". This article provides a nice illustration of my point.
6 min read
Fuzzy Name Matching in Postgres
The page "Falsehoods Programmers Believe About Names" covers some of the ways names are hard to deal with in programming. This post will ignore most of those complexities, and deal with the problem of matching up loose user input to a database of names.
6 min read
Using PostgreSQL to Shape and Prepare Scientific Data
Today we are going to walk through some of the preliminary data shaping steps in data science using SQL in Postgres.
9 min read
R Predictive Analytics in Data Science Work using PostgreSQL
Today we are going to finish up by showing how to use that stored model to make predictions on new data. By the way, I did all of the Postgres work for the entire blog series in Crunchy Bridge. I wanted to focus on the data and code and not on how to run PostgreSQL.
8 min read
Using R in Postgres for Logistic Regression Modeling
Greetings friends! We have finally come to the point in the Postgres for Data Science series where we are not doing data preparation. Today we are going to do modeling and prediction of fire occurrence given weather parameters… IN OUR DATABASE!
8 min read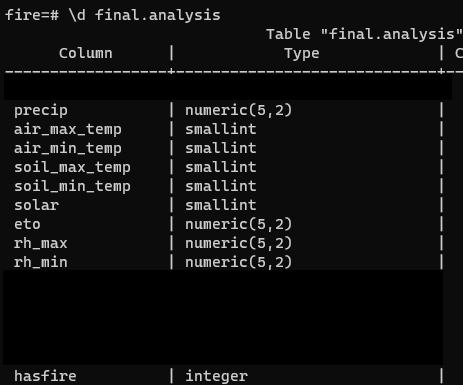
Using PL/pgSQL to Calculate New Postgres Columns
In our last blog post on using Postgres for statistics, I covered some of the decisions on how to handle calculated columns in PostgreSQL. I chose to go with adding extra columns to the same table and inserting the calculated values into these new columns. Today’s post is going to cover how to implement this solution using PL/pgSQL.
8 min read





